

Session 1-1
A Visualization and Analysis System for Japanese Language Change: Quantifying Lexical Change and Variation using the Serial Comparison Model
- Bor Hodošček (Meiji University)
- Makiro Tanaka (Meiji University)
- Hilofumi Yamamoto (Tokyo Institute of Technology / University of California)
This paper introduces an online system for the visualization and analysis of Japanese language change spanning a little over a century (1874–2008). The scale and depth of possible analyses of diachronic linguistic change has been greatly increased through the efforts of large book digitalization projects such as the Google Books corpus (Michel et al., 2011) as well as more curated historical corpora such as the Corpus of Historical American English (COHA) (Davies, 2010). Furthermore, these resources are supplemented with online search interfaces offering relatively complex query capabilities, including POS and syntactic annotation based search queries (Davies, 2011). The present situation for the diachronic analysis of Japanese language corpora is not developed to the same extent: while corpora representing different time periods and genres are available, they are isolated and encoded in incompatible formats. Furthermore, while some of them provide search interfaces (Chūnagon and NINJAL-LWP are two such examples), the incomplete coverage of corpora and lack of focus on diachronic analysis means that the analysis workflow is not as streamlined and automated as it is for English. Having provided some of the motivations for developing the system, we detail the corpora and processing methodologies to be used in constructing the system, as well as introduce the role of the Serial Comparison Model in quantifying lexical language change.
The following five corpora are used as a sample of modern and contemporary written Japanese:
- The Balanced Corpus of Contemporary Written Japanese (c. 1975–2008)
- The Sun corpus (c. 1895–1925)
- The Meiroku Zasshi corpus (c. 1874–1875)
- The Kindai Josei Zasshi corpus (c. 1894–1925)
- A subset of the Aozora Bunko (c. 1890s–)
The present collection of corpora does not evenly cover the different genres of Japanese as is the case in some other diachronic corpora such as COHA (Davies, 2013). However, through the use of metadata such as the Nippon Decimal Classification (NDC) system, date of publication, and other available metadata on the authors, well-specified subsets of the collection can nevertheless provide insights into language change in the context of the user's query.
All text is processed into morpheme tokens using the morphological analyzer MeCab and, depending on the time period, the modern or contemporary version of the UniDic morphological dictionary. A unique property of both variants of UniDic is their organization of word tokens under lemma that cover the many orthographic variants observed in Japanese writing. Taking the basic lemma-word orthography pairs as a base, we construct cooccurrence networks between all words occurring in the same sentence or paragraph. This cooccurrence network is constructed so that we are able to generate sub-networks that match some metadata query, such as year and NDC code, which can then be used to compare with other sub-networks.
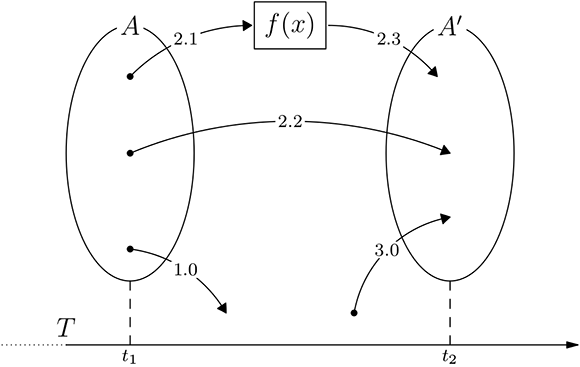
The Serial Comparison Model (SCM) introduced in Yamamoto, Tanaka, and Kondo (2012) models lexical changes occurring between two reference frames. Taking as an example a diachronic analysis between two corpora A and A' sampled from different time periods t and t' , the model provides five classification codes representing the different possible transitions of a word between two time periods (Fig. 1). Using this model and its categorization scheme, we will visualize changes within a lemma's cooccurrence network in the transition between two or more time periods.
Reference
- Davies, M.: The Corpus of Historical American English: 400 million words, 1810–2009, (2010), http://corpus.byu.edu/coha/ (visited on 05/07/2014).
- Davies, M.: Google Books (American English) Corpus (155 billion words, 1810–2009), (2011). http://googlebooks.byu.edu/ (visited on 05/07/2014).
- Davies, M.: “Google Scholar and COCA-Academic: Two Very Different Approaches to Examining Academic English,” Journal of English for Academic Purposes, Vol. 12, No. 3, pp. 155–165 (2013).
- Michel, J.-B. et al.: “Quantitative Analysis of Culture using Millions of Digitized Books,” Science, Vol. 331, No. 6014, pp. 176–182 (2011).
- Yamamoto, H., Tanaka, M. and Kondo, Y.: “Diachronic Corpus and Linguistic Space: New Methods for the Analysis of Language Change,” The 13th ACIS International Conference on Software Engineering, Artificial Intelligence, Networking and Parallel & Distributed Computing (SNPD), IEEE, pp. 381–384 (2012).